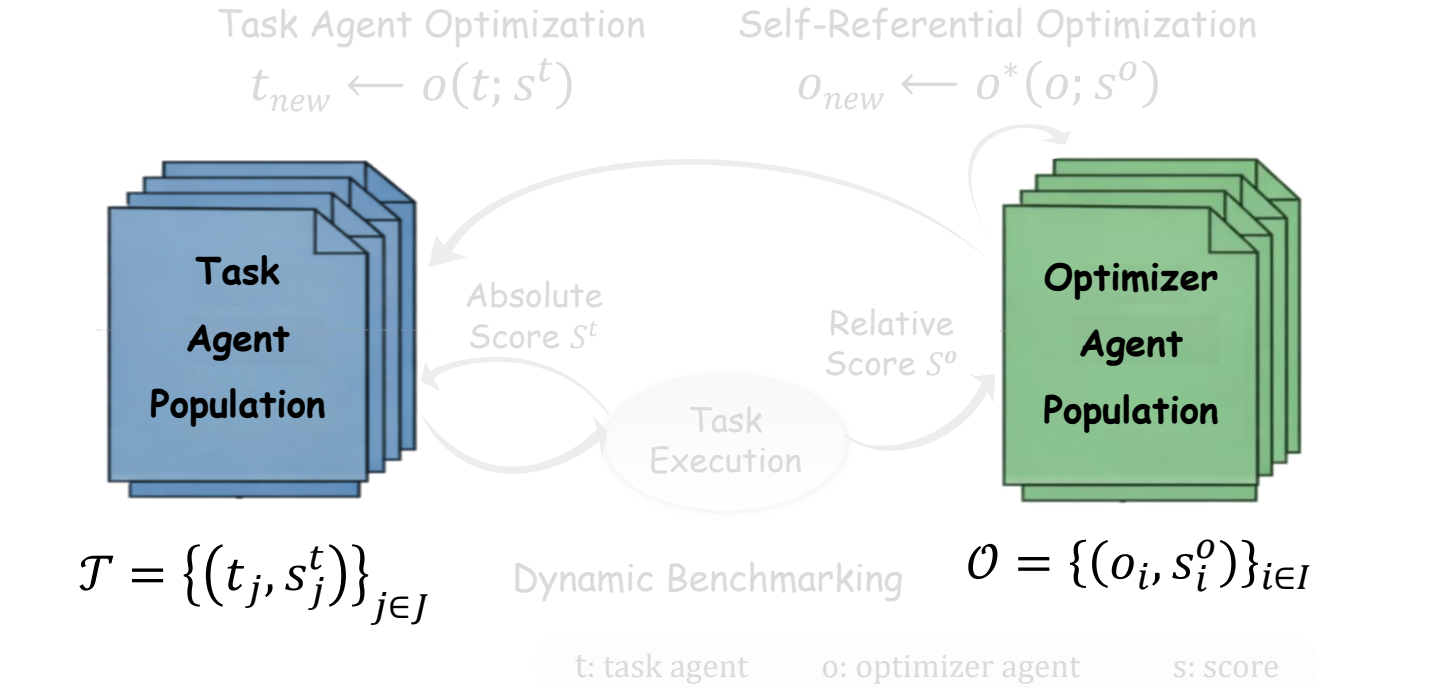
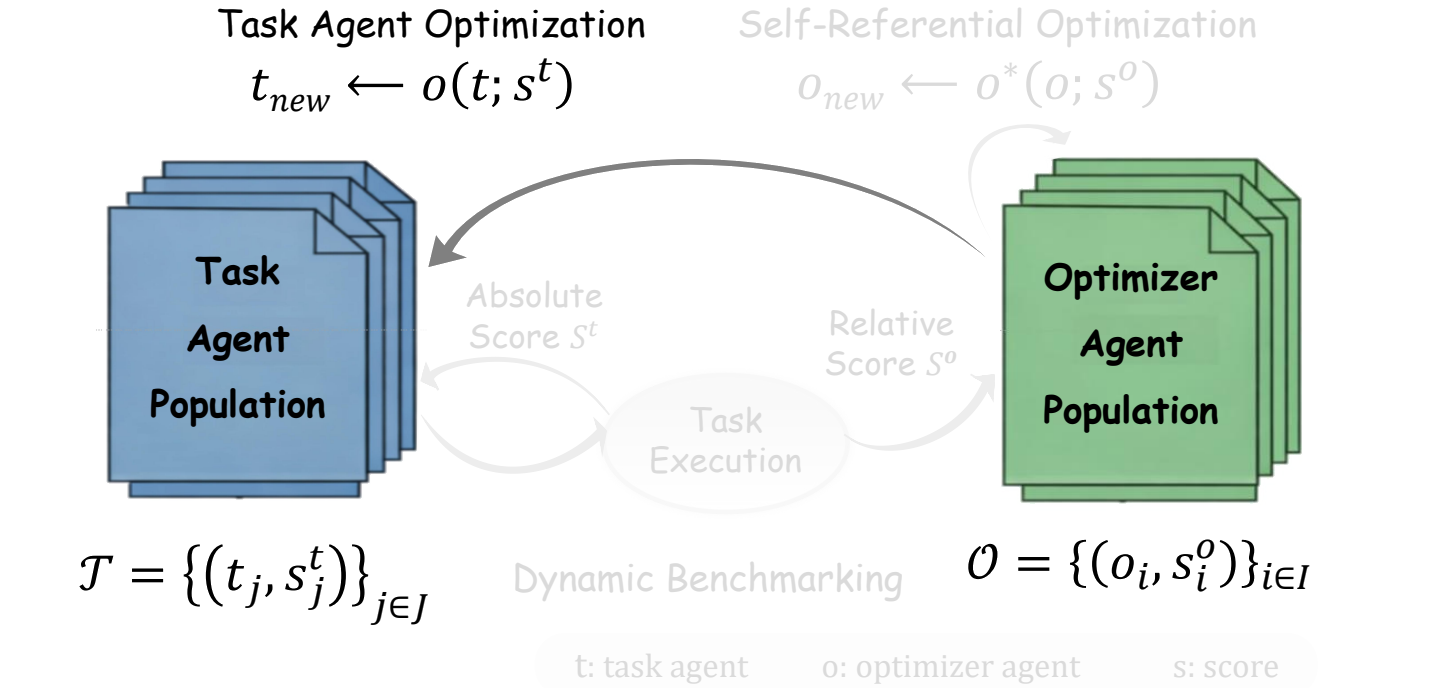
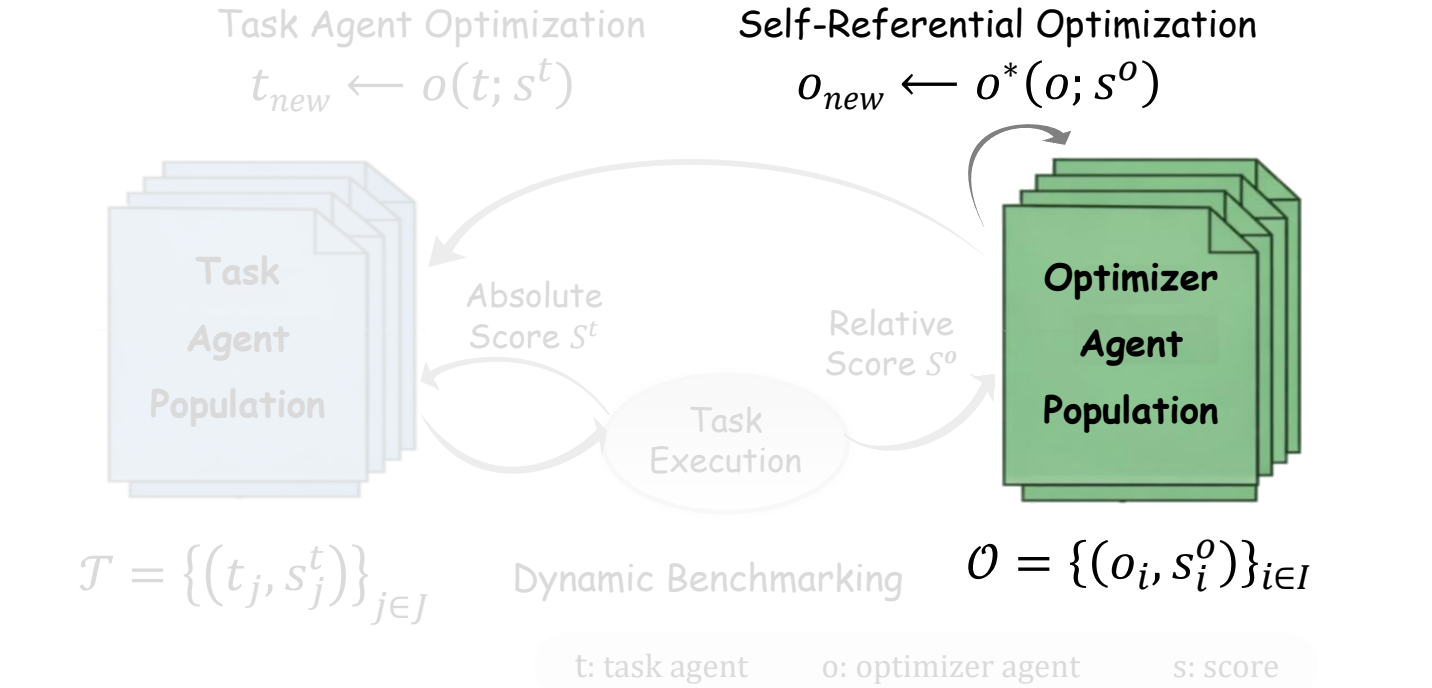
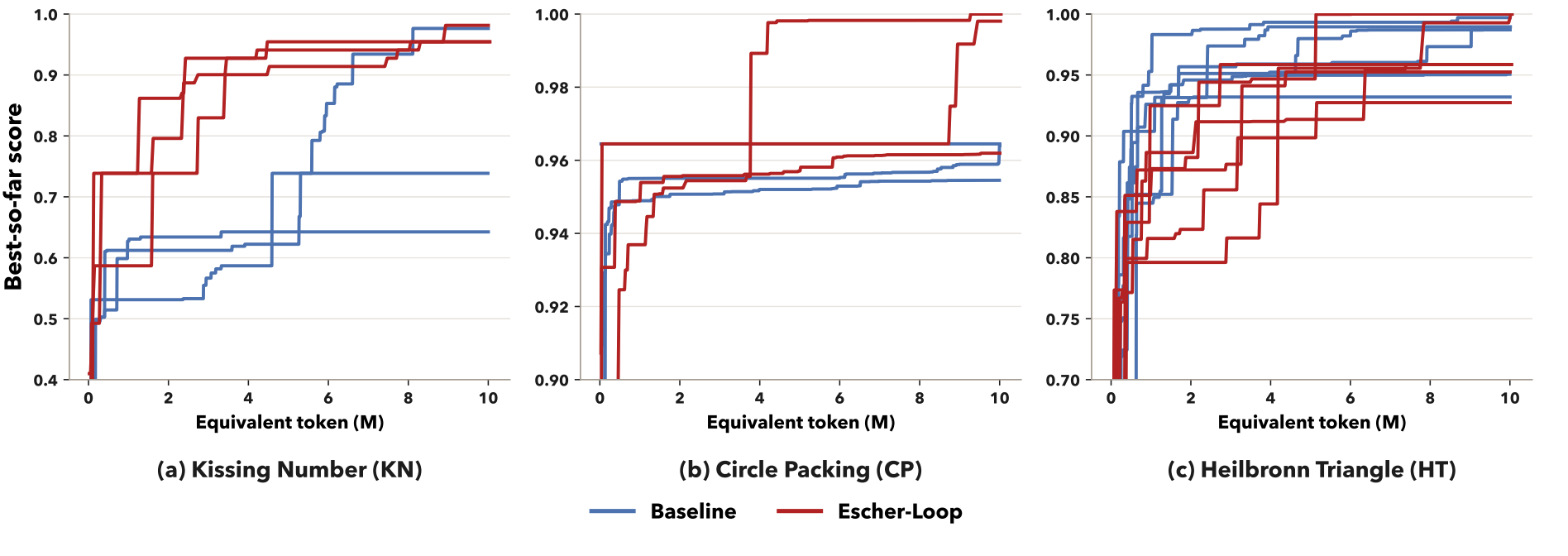
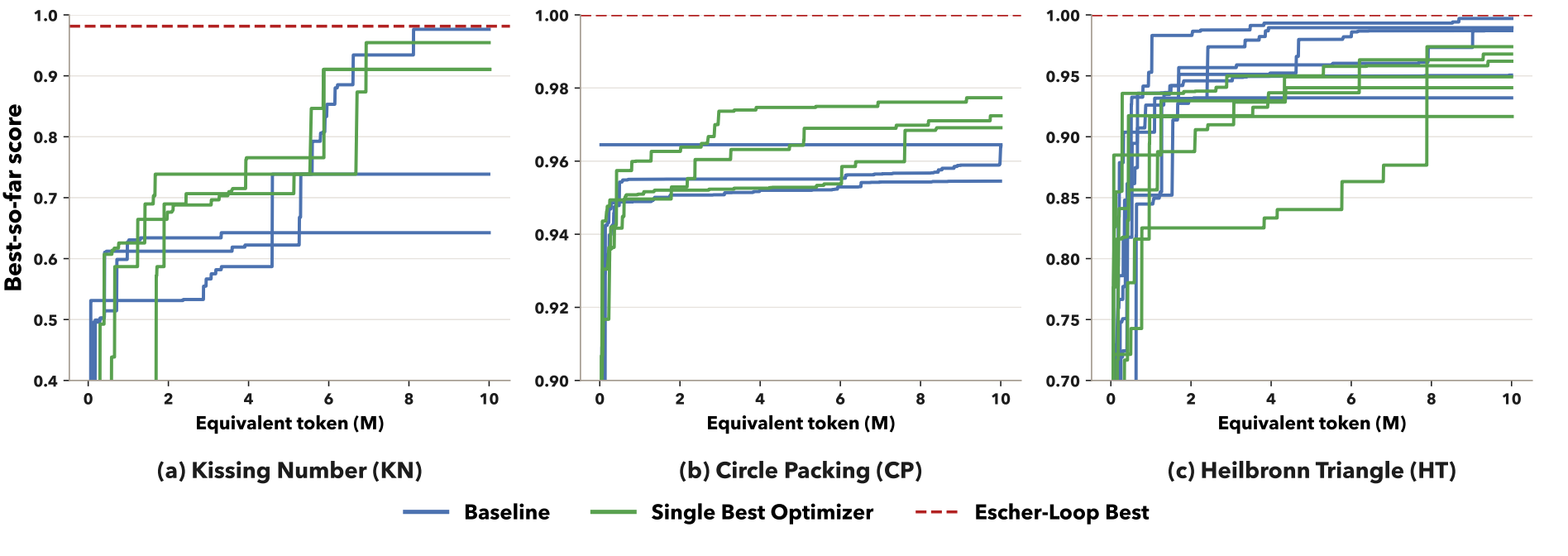
The key move is operational rather than philosophical. If an optimizer repeatedly generates task agents with stronger empirical scores, then its optimization capability has improved. The optimizer is no longer an invisible workflow around the agent; it becomes an agent population with scores, competition, and evolution.
关键不是抽象哲学定义,而是可操作定义:如果一个优化器不断生成得分更高的任务智能体,那么它的优化能力就提升了。优化器不再是智能体系统外部不可见的流程,而是一个拥有分数、竞争和演化的智能体种群。
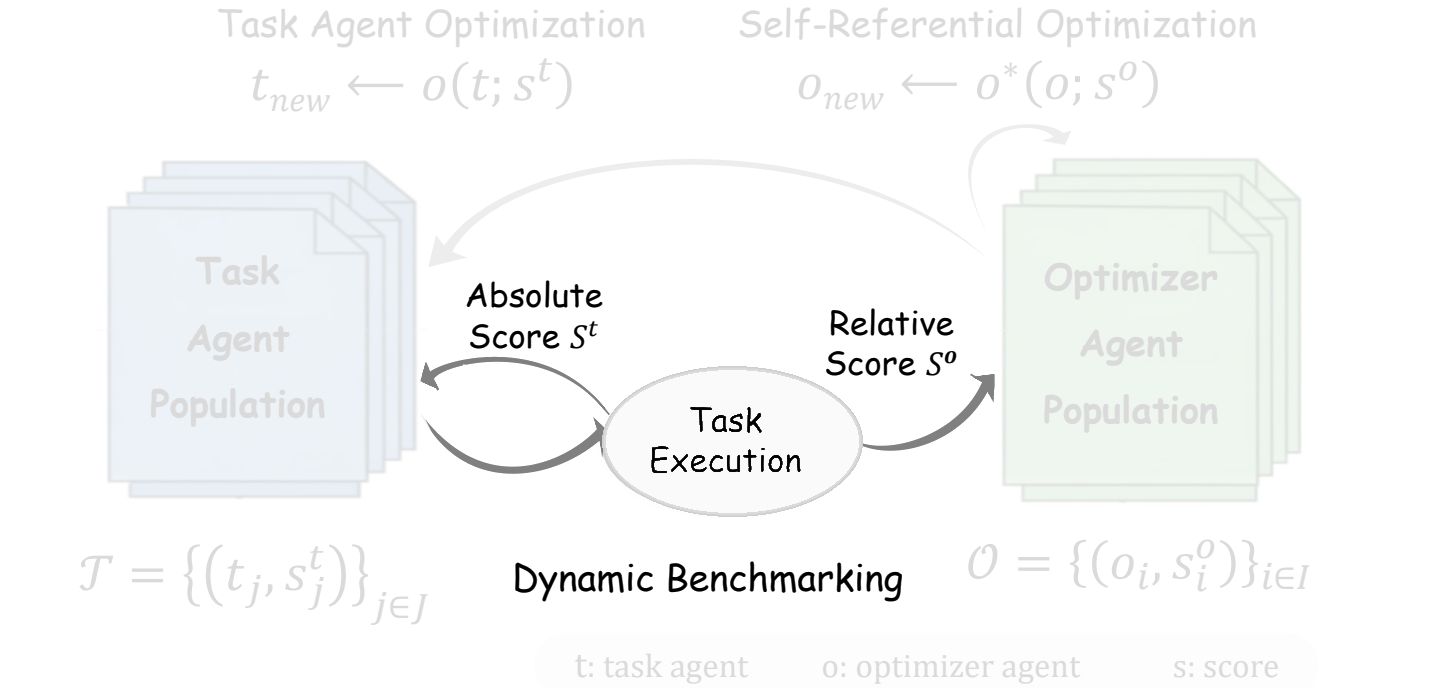
Task feedback is the bridge: one execution improves the task population and evaluates the optimizer population.
任务反馈是桥梁:同一次执行既改进任务种群,也衡量优化器种群。